Cet article présente une réalisation d’auto-scaling sur Kubernetes appliqué à une charge importante et fluctuante de Builds Docker dans un environnement GitLab CI/CD sur Azure.
Un des avantages les plus fréquemment cités du cloud public est sa capacité d’auto-scaling. Pourtant dans la pratique, l’auto-scaling est souvent délicat à mettre en oeuvre, les points d’attention sont notamment :
- Trouver les bons seuils et mécanismes de déclenchement pour que le scaling soit effectif
- S’assurer que les pics de charge ne soient pas plus rapides que l’auto-scaling, au risque que l’application ne se trouve en rupture avant que le provisioning ne soit effectif,
- Vérifier que l’auto-scaling fonctionne bien également à la baisse pour réduire les ressources et donc les coûts
Nous verrons comment cette charge de travail de Build Docker, devenue très conséquente, a été réintégrée dans le cluster Kubernetes avec un auto-scaling qui a permis de fiabiliser les builds Docker, et donc les déploiements applicatifs, tout en réduisant par 3 les coûts d’infrastructure.
Le contexte : un ensemble de sites e-commerce B2B multimarques sur le cloud Azure
L’entreprise est un groupe de négoce de plusieurs milliards d’euros de chiffre d’affaires, qui réalise une partie croissante de son activité en ligne. Elle opère un grand nombre de sites e-commerce de négoce B2B développés sous deux CMS distincts et déclinés sous différentes marques.
Alfa-Safety a accompagné le client dans la migration de ses applicatifs digitaux sur Azure , en intégrant les méthodologies DevOps avec une chaîne de CI/CD complètement automatisée pour apporter aux équipes de développement beaucoup plus d’agilité et de vélocité dans les déploiements applicatifs.
Alfa-Safety assure également l’infogérance 24/7 de l’ensemble des applications digitales du groupe migrées sur Azure : supervision, traitement des demandes et incidents, mises à jour et évolutions, garantie de SLA, optimisation FinOps.
La problématique : une charge très élevée de Builds Docker
Les applications digitales sont déployées sous Docker sur un cluster Kubernetes sur Azure. La CI/CD est basée sur GitLab.
Le rythme de développement est très soutenu avec des mises à jour hebdomadaires, et du fait des déclinaisons des sites sous différentes marques/activités, un nombre élevé de builds Docker est déclenché en parallèle depuis GitLab.
Ces builds sont eux-mêmes assez lourds unitairement, notamment du fait des tâches de compilation de Javascript.
A l’origine, des jobs de builds exécutés dans un Pod dédié sous Kubernetes
A l’origine, ces jobs de build Docker étaient exécutés dans un cluster K8S dit “outils”, sur un node pool “Runner GitLab” , mais dans un Pod unique. Des contraintes techniques ne permettaient pas alors de paralléliser les jobs dans des Pods différents.
Cette architecture simple a fonctionné correctement en début de projet.
La multiplication des jobs sature la capacité au sein de K8S
Avec l’extension du périmètre et la multiplication des projets de développement, la charge de build Docker est devenue trop lourde pour le Pod chargé du build,
Des difficultés de configuration des builds Docker ne permettaient pas de multiplier les Pods au sein du cluster K8S :
- Pas de dynamisme pour répartir de la charge de builds sur plusieurs Pods et les scaler.
- Absence d’isolation entre les jobs ; si bien qu’une surcharge ponctuelle pouvait pénaliser l’ensemble des jobs.
Une solution de contournement sur VM dédiée
Ces difficultés devenant pressantes, la décision a été prise de déporter les Builds Docker à l’extérieur du Cluster Kubernetes sur une VM dédiée, une approche pragmatique mais qui a rapidement présenté de nouvelles contraintes :
- La VM a dû être redimensionnée à la hausse à plusieurs reprises pour faire face aux besoins toujours croissants de build, jusqu’à atteindre 48 vCPU et 96 Go Ram,
- Le coût mensuel atteignait environ 1 700 €, bien au-delà du budget prévu,
- Le lancement en parallèle de plusieurs jobs lourds générait des pics de charge qui saturaient régulièrement les ressources de la VM dédiée,
- Les builds en échec laissaient les Jobs GitLab en suspens, contraignant les développeurs à surveiller ces derniers constamment,
- Ces saturations se produisaient aux moments les plus critiques pour les mises en production,
- La facture FinOps de la VM ne cessait d’augmenter,
- Sur le cluster Kubernetes subsistait le node pool GtiLabRunner qui continuait à traiter les autres jobs GitLab (hors build Docker), représentant un coût additionnel à celui de la VM dédiée.
Cette situation insatisfaisante a perduré quelques mois avant qu’il ne soit décidé de consacrer du temps pour étudier une alternative.
L’équipe infrastructure a donc travaillé à une solution permettant de réintégrer les builds Docker dans le cluster Kubernetes en s’appuyant sur le mécanisme d’auto-scaling de ce dernier pour permettre d’absorber les pics de charge.
La solution : réintégration des Builds Docker dans Kubernetes avec auto-scaling
Une solution pour paralléliser les Builds Docker sous Kubernetes
Le travail a commencé par une étude de configuration permettant d’exécuter efficacement les jobs de build Docker dans des Pods indépendants sous Kubernetes.
La solution retenue repose sur les mécanismes suivants :
- L’adoption de Buildx pour builder en parallèle pour différentes architectures de processeurs (Mac ou PC)
- L’attribution de “droits privilégiés” aux pods de build, droits nécessaires à l’exécution du Daemon Docker, tout sécurisant ces droits par des mécanismes de contrôle d’accès Kubernetes (RBAC, pod security policies),
- Une organisation 1 job = 1 pod , chaque job GitLab est exécuté dans un Pod, contenant 1 ou plusieurs conteneurs ainsi qu’un “sidecar”
- L’utilisation d’un Sidecar par pod : chaque pod embarque un sidecar qui lui confère une indépendance complète vis-à-vis des autres jobs, facilite la gestion fine des ressources et assure l’isolation,
- Le timeout d’un job a été augmenté afin de laisser le temps à l’auto-scaling d’ajouter un ou plusieurs nodes avant qu’un job ne passe en échec,
Ainsi chaque pipeline déclenché depuis GitLab lance plusieurs jobs parallèles , chacun dans un Pod avec 1 runner et son sidecar :
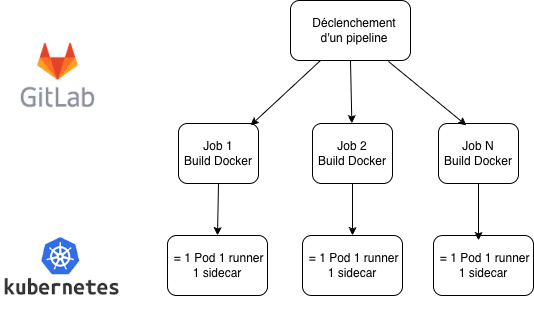
Reconfiguration du node pool GitLab Runner avec auto-scaling
Les Jobs de build Docker ont été réintégrés dans le node pool “GitLab Runner” qui, de statique avec une charge assez faible et constante, a été reconfiguré pour assurer un auto-scaling efficace :
- Passage sur des VMs de taille intermédiaire, 8 CPU 32 Go RAM, assez conséquentes pour offrir une capacité de base suffisante pour plusieurs pods avec de la flexibilité, mais assez granulaires pour permettre un scaling progressif,
- Configuration du node pool avec un minimum de 2 VMs et un maximum de 10,
- Auto-scaling assuré par Kubernetes qui se charge seul d’augmenter et réduire le nombre de nodes dans le pool en fonction de la charge CPU/RAM, aucune configuration spécifique n’est ajoutée.
Les résultats: fiabilité, réactivité et réduction des coûts
Le profil de charge et l’auto-scaling
Le graphique ci-dessous montre le profil d’une journée de semaine type et illustre parfaitement le fonctionnement de l’auto scaling, la montée en charge (scale-up) et la réduction (scale-down) du node pool :
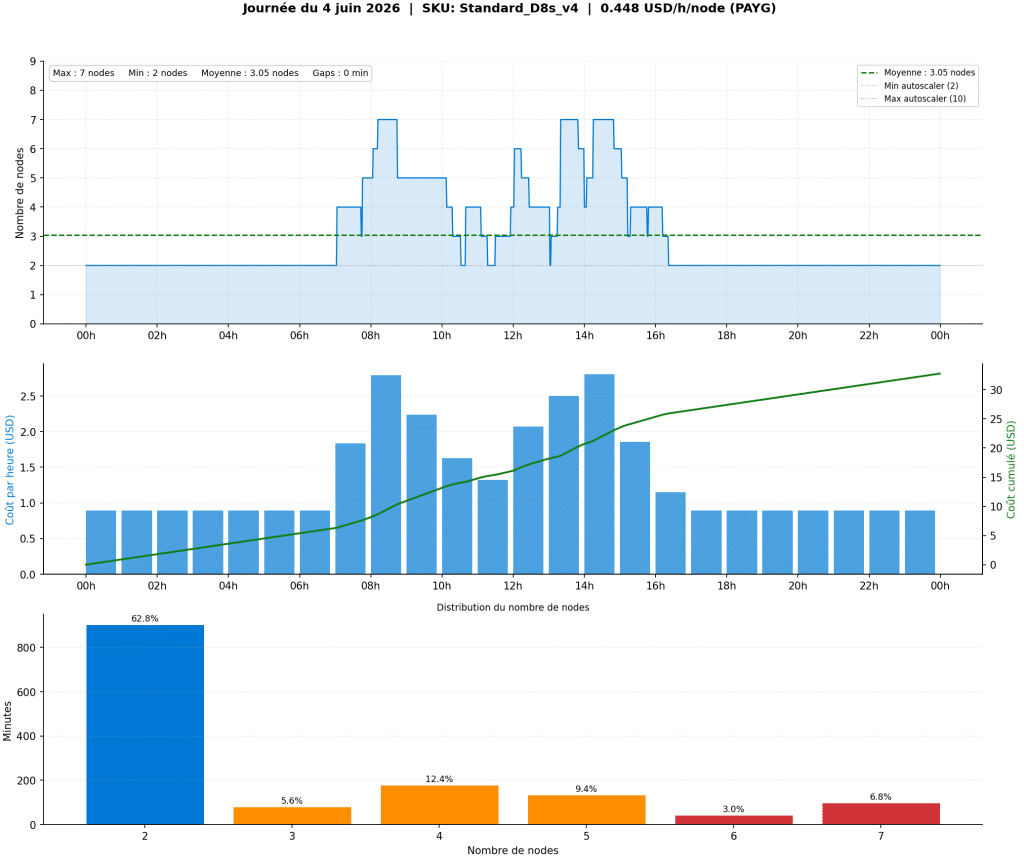
On observe notamment que :
- La plage d’utilisation intensive est concentrée entre 7h et 17h
- Sur 24h, près des deux tiers du temps, le node pool tourne en configuration minimale
- Moins de 20% du temps, le node pool atteint et parfois dépasse la capacité de l’ancienne VM dédiée,
- Le scaling ajoute et retire des noeuds plusieurs fois dans la journée, parfois 2 voire 3 à la fois, selon la charge mesurée,
- Le maximum de 10 nodes n’a jamais été atteint, le pic de charge mobilise parfois jusqu’à 7 nodes, mais jamais plus d’une heure de suite,
- Le minimum a été maintenu à 2, le gain marginal de le réduire à 1 n’a pas été jugé suffisant par rapport à la souplesse de disposer d’emblée chaque matin de 2 VMs disponibles.
Une meilleure disponibilité pour les développeurs et DevOps
Le premier bénéfice est la qualité de service pour les développeurs et les devOps:
- Plus aucun job de build en échec,
- Les pipelines GitLab ne risquent pas de rester en suspens, et donc arrêt de leur surveillance manuelle par les développeurs
- Le planning de déploiement n’est plus retardé ou impacté pour des soucis de capacité d’infrastructure
Simplification du travail de l’équipe infrastructures
Le deuxième bénéfice est pour l’équipe infrastructure qui n’a plus à gérer les incidents de saturation, veiller à la relance des services, se coordonner avec les développeurs, étudier une augmentation de la VM et justifier les dépassements de budget.
Au global, un gain très significatif en fluidité et sérénité pour l’ensemble des équipes, développement, DevOps et Infra.
Une réduction des coûts par 3
Le troisième bénéfice est clairement un gain financier:
- Une journée type du node pool GitLab Runner reconfiguré coûte 32 $ , soit sur 20 jours travaillés en moyenne 640 $, ce qui représente le tiers des coûts cumulés de la VM dédiés + le node pool GitLab Runner qui avait été conservé, soit un gain de 1 200 $ par mois,
- Le temps passé pour imaginer, configurer, tester et valider la solution a été de 6 JH, soit un ROI largement inférieur à 6 mois en ne considérant que le gain sur les coûts d’infra. En intégrant le gain sur les temps auparavant passés par les différentes équipes à gérer les dysfonctionnements, le ROI est bien inférieur à 3 mois.
Enseignements et bonnes pratiques
Ce qui a rendu cette solution possible
- Un profil de charge bien adapté à l’auto-scaling : fluctuations fortes, pic concentré sur la journée de travail, avec des creux importants la nuit et le week-end.
- La tolérance aux délais de provisionnement : un job de build peut attendre 2 à 3 minutes le démarrage d’un nœud sans impact métier. Ce n’est pas le cas pour toutes les charges de travail, comme un pic soudain de fréquentation.
- L’architecture 1 job = 1 pod garantit l’isolation et évite les effets de bord entre jobs concurrents.
- Le choix de granularité des VMs du node pool (8 vCPU / 32 Go) a permis un auto-scaling progressif et précis, sans sur-provisionnement.
- Une approche full DevOps et la bonne collaboration entre les différents intervenants : Développement, DevOps et Infra, la solution a été recherchée, évaluée, qualifiée en commun.
Points de vigilance
- Assurer une surveillance de la charge et du fonctionnement de l’auto-scaling, ne pas sous-estimer le temps de scale-up pour les charges très soudaines ou massives, il faudra peut être réévaluer à un moment le minimum du node pool, ou la taille des VMs,
- La sécurisation des pods avec « droits privilégiés » est critique : elle doit être traitée dès la conception, pas ajoutée a posteriori.
- Le timeout GitLab doit être soigneusement calibré : trop court, les jobs échouent pendant le scale-up ; trop long, les vrais échecs sont masqués.
Ce projet illustre l’intérêt d’une architecture Kubernetes bien configurée pour gérer la diversité des charges de travail et absorber des variations de charge. Le double scaling des Pods et du node pool permet une combinaison très efficace.
La clé réside dans l’adéquation entre le profil de charge, la granularité des ressources et les tolérances opérationnelles du contexte métier.
Pour Alfa-Safety, cette réalisation s’inscrit dans une approche DevOps et FinOps systématique :
- La dimension DevOps des projets d’infra est incontournable,
- L’efficacité de la chaîne de déploiement CI/CD est un facteur de productivité et d’agilité pour les équipes de développement comme pour toute l’entreprise,
- Kubernetes est une plateforme extrêmement puissante, mais qui nécessite une véritable expertise pour résoudre les situations complexes,
- Le FinOps est une démarche qui permet d’identifier des coûts inadaptés et d’engager des travaux d’optimisation.
Vous opérez des charges CI/CD sur Kubernetes et vous cherchez à fiabiliser vos pipelines, optimiser votre infrastructure et réduire vos coûts cloud ?
Pour faire un état des lieux de votre plateforme Kubernetes, consultez notre article sur l’intérêt de réaliser un audit Kubernetes.
